Microservice Patterns
Проработать
- Saga vs Two face commit
- A pattern language for microservices
- Архітектурні Патерни у Сучасних Мікросервісах - Java: Про ІТ під каву - #36
- Собеседование на Сеньора | Проектирование архитектуры систем | Systems Design
- Как подготовиться и пройти System Design Interview. Александр Поломодов
- Service Discovery в распределенных системах на примере Consul. Александр Сигачев
- Знакомимся с Event Sourcing. Часть 1
- Что спрашивают о микросервисах в крупных компаниях | Senior Developer | Jetbulb
- Стратегии обработки ошибок: Circuit Breaker pattern
- Circuit Breaker паттерн
- Шпаргалка по миграции монолита на микросервисы
- Database per Microservice паттерн
- Top 7 Ways to 10x Your API Performance
- API Gateways in System Design Interviews w/ Ex-Meta Staff Engineer
- Как управлять транзакциями в микросервисной архитектуре
- Saga паттерн и распределенные транзакции
Saga
Основные разделы
System Design Interview
- Узнать все требования.
- Количество юзеров.
- Функциональные требования.
Решение проблем
Durability
Сервис упал, сеть оборвалась, брокер перегружен, сообщение потерялось или выполнилось дважды. Уменьшение риска каскадных отказов.
- Retry(Повторная попытка)
- Circuit Breaker(Предохранитель)
- Idempotent Consumer/Idempotent Endpoint
- Dead Letter Queue (DLQ)
- Transactional Outbox
- Bulkhead (Перегородки)
- Message Persistency (Durable Queues)
Поддержка транзакций между микросервисами.
- Saga
- TCC(Try-Confirm-Cancel) - резервирует ресурсы на этапе try, подтверждает через confirm, если все части успешны, или отменяет через cancel при ошибке. Часто используется для бронирований и платежей.
Симметричное распределение нагрузки и сложности бизнес-логики.
Для обеспечения последовательных изменений между микросервисами в состояние приложения.
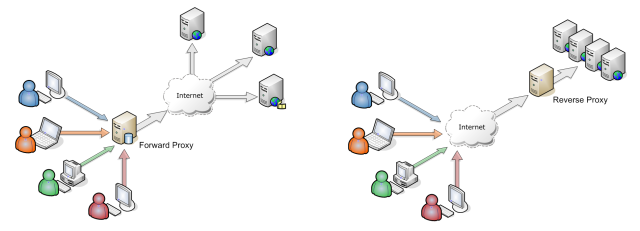
Прокси сервера(Proxy):
- Прямой прокси(Forward Proxy) - используется клиентом, таким как веб-браузер. Клиент знает за этот прокси и осознанно его использует для обхода блокировок и других задач. Используется для сокрытия работы пользователя.
- Обратный прокси(Reverse proxy) - используется сервером, таким как веб-сервер. Клиент не знает за этот прокси и не осознанно его использует для распределения нагрузок, дополнительной защиты, кэширования и тд. Используется для сокрытия работы сервера.
Для чего используется
- SSL termination
- Caching
- Security
- Compression - архивирования контента.
Имплементации
- Nginx
- HAProxy
- Caddy
- Apache
Load Balancing
Load Balancing - это Reverse proxy который делает только одну вещь - распределение запросов на несколько серверов.
Для чего
- Scalability - обработка большего количества запросов через добавление серверов.
- Availability - если один сервер отказывает, другие его заменяют.
Алгоритмы
- Round Robin - распределение по очереди.
- Least Connections - запросы шли на тот сервер, у которого меньше всего активных соединений в данный момент.
- IP Hash - клиенты строго привязаны к серверам. Например по IP, ID, Region etc.
- Weighted - разделение серверов по мощности и распределение запросов от этого. Более можный - больше запросов.
- Least Response Time - запрос идет на сервер с наименьшим временем ответа.
- Random - сервер выбирается случайным образом.
- Least Bandwidth - запрос идет на сервер с наименьшей текущей загрузкой сети.
Примеры
- NGINX
- HAProxy
- AWS Elastic Load Balancing
- AWS ALB
- AWS NLB
- GCP LB
API Gateway
API Gateway - единая точка входа для клиентов к микросервисам.
- Маршрутизацию запросов
- Аутентификацию/авторизация
- Rate limiting
- Агрегацию ответов
- Logging
- Transform - стандартизация формы ответа.
- Analytics and Monitoring -
Примеры
- Kong
- AWS API Gateway
- Apigee
- Azure APIM
- Tyk
- Amazon API Gateway
- Spring Cloud Gateway
Saga
Saga - если мы используем паттерн "Database per Microservice" нам нужно обеспечить согласованность данных между сервисами. Управляет распределёнными транзакциями без глобальной блокировки.
Каждый сервис выполняет транзакцию в своей базе и публикует событие.
Ошибки обрабатываются компенсирующими транзакциями.
Реализуется через хореографию или оркестрацию.
Способы координации саг:
Хореография(Choreography)
Хореография(Choreography) - каждая транзакция публикует события, которые запускают транзакции в других
сервисах.
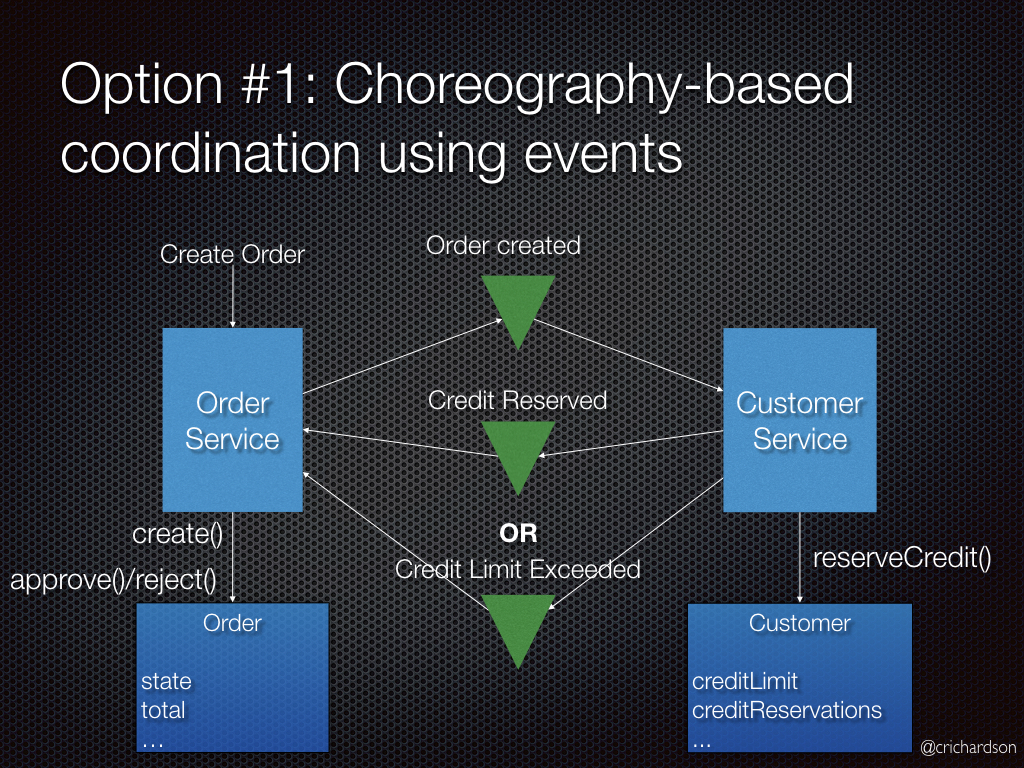
Будут выполнены следующие шаги:
- Order Service (Сервис Заказа) создает Order (Заказ) в статусе pending (в ожидании) и публикует событие OrderCreated (ЗаказСоздан).
- Customer Service (Сервис Клиента) получает событие и пытается зарезервировать кредит для заказа. После чего публикует одно из двух событий: CreditReserved (КредитЗарезервирован) или CreditLimitExceeded (КредитныйЛимитПревышен).
- Order Service (Сервис Заказа) получает событие и изменяет состояние заказа в approved (подтвержден) или cancelled (отменен).
Оркестровка (Orchestration)
Оркестровка(Orchestration) - оркестратор говорит участникам, какие транзакции должны быть запущены.
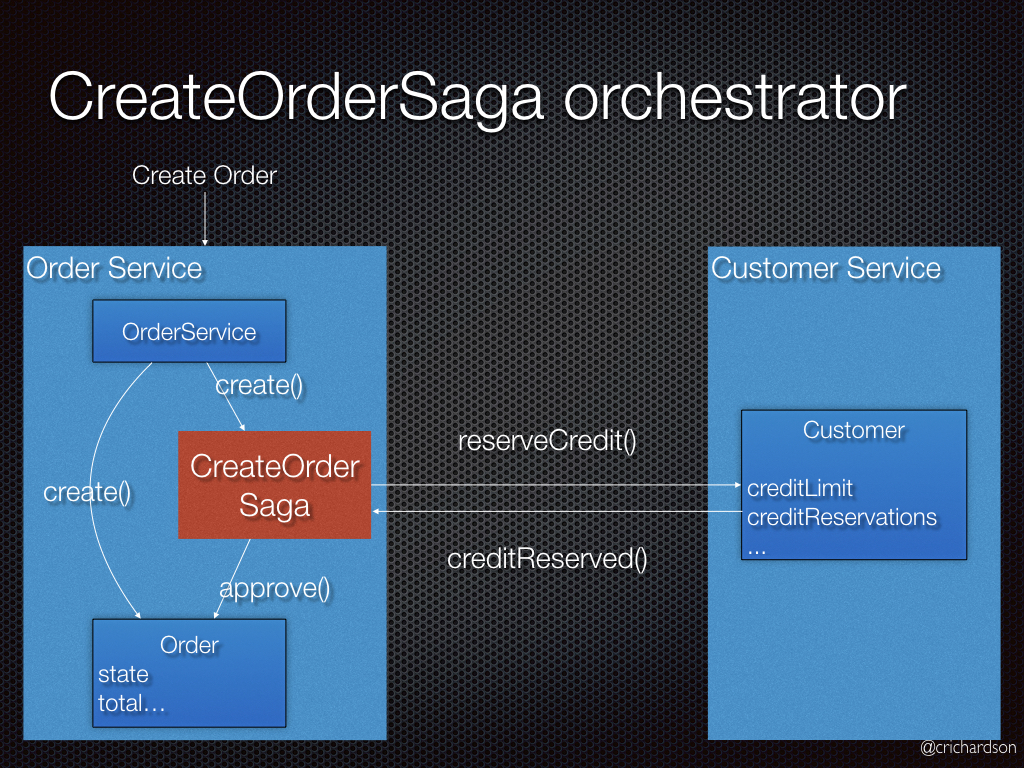
Будут выполнены следующие шаги:
- Order Service (Сервис Заказа) создает Order (Заказ) в статусе pending (в ожидании) и создает CreateOrderSaga (СагаСозданияЗаказа).
- CreateOrderSaga (СагаСозданияЗаказа) отправляет команду ReserveCredit (ЗарезервироватьКредит) в Customer Service (Сервис Клиента)
- Customer Service (Сервис Клиента) пытается зарезервировать кредит для заказа и отправляет назад ответ
- CreateOrderSaga (СагаСозданияЗаказа) получает ответ и отправляет ApproveOrder (ПодтвердитьЗаказ) or RejectOrder (ОтменитьЗаказ) команду в Order Service (Сервис Заказа)
- Order Service (Сервис Заказа) изменяет состояние заказа в approved (подтвержден) или cancelled (отменен)
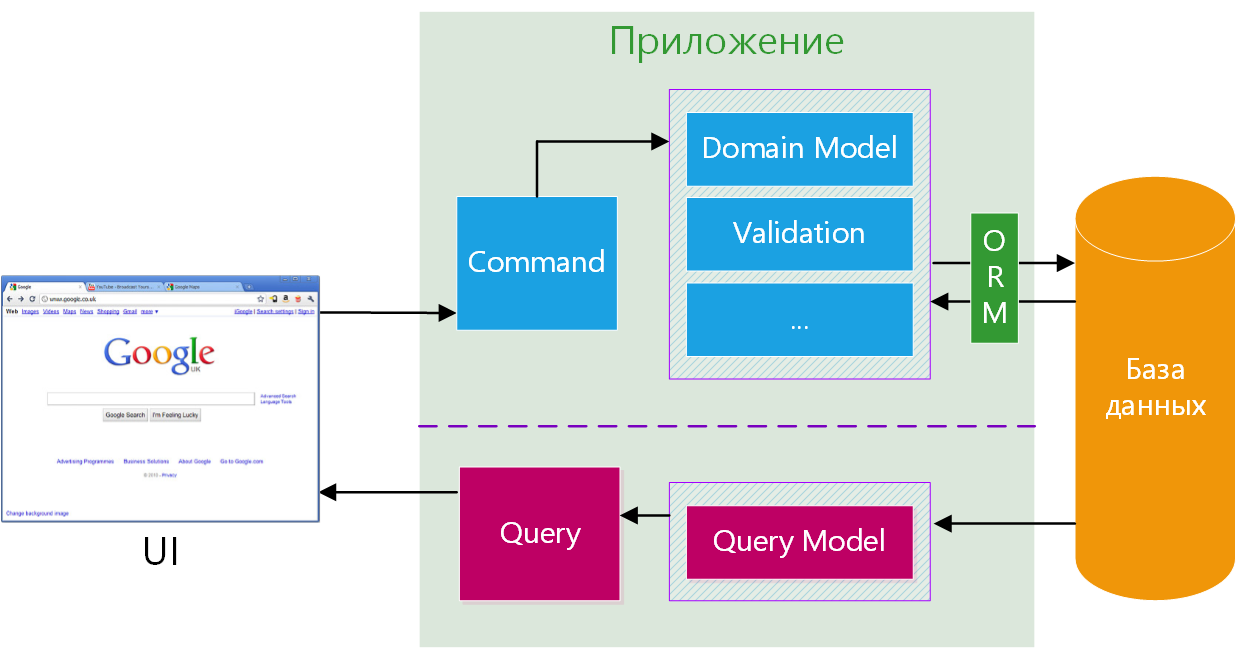
Command and Query Responsibility Segregation(CQRS)
CQRS — это стиль архитектуры, в котором операции чтения отделены от операций записи.
Решает проблему - не симметричное распределение нагрузки и сложности бизнес-логики на read(Query) и write(Command) - подсистемы Большинство бизнес-правил и сложных проверок находится во write — подсистеме. При этом читают данные зачастую в разы чаще, чем изменяют.
Недостатки
- Дубликат кода
- Большое количество запросов, для поддержки консистентность.
Event sourcing
Event sourcing - архитектурный шаблон. Все изменения, вносимые в состояние приложения, сохраняются в той последовательности в которой они происходили.
Помогает эффективно распределять данные между микросервисами.
Преимущества:
- Хранения не объектов, а событий изменения состояний помогает консистенции.
- Надежная система аудирования событий(audit logging).
- В любой момент можно получить актуальное состояние.
- Пониженное сцепление между сущностями.
Недостатки:
- Нужно поддерживать событийность.
- Необходимо реализация CQRS.
- Необходимость поддерживание консистентность.
Database per Microservice
Database per Microservice - микросервисы не имеют доступа к базе соседних сервисов и обращаются между собой средством REST, или через message broker.
Преимущество
- Слабая связанность сервисов. Изменения в бд одного сервиса не влияют на другие сервисы как при Shared Database паттерне.
- Каждый сервис может использовать тот тип БД который подходит лучше для его нужд. Например: один сервис может использовать Elastic поиск, второй NoSQL, третий SQL, если этого требует бизнес логика и NFR.
Недостатки
- Реализация бизнес-транзакций, охватывающих несколько сервисов, довольно комплексное задание. Распределенных транзакций лучше избегать из-за CAP теоремы. Более того, многие современные (NoSQL) базы данных их не поддерживают.
- Реализация запросов, которые джоинит данные с разных баз данных, не тривиальная задача.
- Сложность управления несколькими базами данных SQL и NoSQL.
Retry pattern
Retry pattern - механизм повторения запросов.
Виды:
- Fixed delay - фиксированное время.
- Incremental delay - время между попытками увеличивается.
- Exponential backoff - время между попытками увеличивается экспоненциально.
Circuit Breaker
pattern - защищает сервисы от избыточной нагрузки и отказов.
Помогает "Retry pattern" не добить нагруженный сервис количеством запросов.
Как работает:
- Замеряет ошибки – если система часто отвечает сбоем, то "выключает" запросы.
- Блокирует вызовы – на время переключается в режим отказа (open state).
- Пробует восстановиться – спустя время делает тестовые запросы и, если сервис снова работает, возвращает его в работу.
Timeout pattern
Timeout pattern - ограничивает время ожидания запросов.
Виды timeout:
- Connection timeout - попытка соединения.
- Read/Write(response) timeout - время на запрос.
- Idle Timeout - автоматический разрыв соединения, если оно неактивно в течение определенного времени.
Fallback pattern
Fallback pattern - запасное действие в случае ошибки.
Виды fallback:
- Response by default
- Change client - попробовать другой способ получить данные(если такой есть)
Bulkhead pattern
Bulkhead pattern - используется для изоляции различных компонентов системы, чтобы сбои в одной части не затронули всю систему. Для повышения отказоустойчивости и изоляции сбоев.
Применение Bulkhead pattern:
- Разделение ресурсов — выделение отдельных пулов потоков, соединений с базой данных или очередей сообщений для разных сервисов.
- Изоляция отказов — если один сервис перегружен или выходит из строя, другие продолжают работать.
- Повышение устойчивости — уменьшение риска каскадных отказов.
Publisher–Subscriber(Pub/Sub)
Publisher–Subscriber (Pub/Sub) модель - архитектурный паттерн для обмена сообщениями между компонентами системы, где отправители сообщений (publishers) не знают о получателях (subscribers), а доставка обеспечивается через event bus / broker (например, Kafka, RabbitMQ, Redis Pub/Sub).
Основные идеи:
- Publisher публикует событие (сообщение) в определённый канал/тему (topic).
- Subscriber подписывается на интересующую его тему.
- Message Broker (или шина событий) принимает сообщение от издателя и доставляет всем подписчикам, которые слушают этот канал/тему.
Преимущества:
- Слабая связанность — издатели и подписчики не знают друг о друге напрямую.
- Масштабируемость — легко добавлять новых подписчиков.
- Асинхронность — события можно обрабатывать в разное время.
- Гибкость — разные системы/сервисы могут взаимодействовать через общий брокер.
Недостатки:
- Сложность отладки — трудно проследить, кто именно обработал событие.
- Необходимость брокера — требуется дополнительная инфраструктура (Kafka, RabbitMQ и т.п.).
- Гарантии доставки зависят от реализации брокера (может быть at-most-once, at-least-once, exactly-once).
Реализации:
- Kafka (event streaming)
- RabbitMQ (очереди + pub/sub)
- Redis Pub/Sub (простая реализация)
- Google Pub/Sub, AWS SNS, Azure Event Grid (облачные решения)
Features flag
Feature flag - это приём в разработке, который позволяет включать или выключать определённые функции приложения без деплоя новой версии.
Зачем они нужны?
- Постепенное выкатывание фич (progressive rollout) - можно включить новую фичу сначала 1% пользователей, потом 10%, потом всем.
- A/B-тестирование - показываем разным группам разные варианты интерфейса/логики.
- Возможность быстро выключить фичу - если что-то сломалось → просто выключаем флажок, не делая откат деплоя.
- Раздельное развитие - несколько команд могут работать над функциями, которые ещё не готовы, но уже находятся в кодовой базе.
- Безопасный деплой - код уже в проде, но скрыт до момента включения флага.
Виды feature flags
- Release flags - для постепенного и безопасного релиза новой фичи.
- Experiment flags - для экспериментов и A/B тестов.
- Ops flags - для аварийного отключения компонентов (например, дорогих по ресурсам задач).
- Permission flags - включают функции только определённым пользователям, ролям или тарифам.
Где хранятся флаги?
- В конфиге на сервере
- В базе данных
Минусы
- Фич-флаги надо чистить после использования, иначе код превращается в хаос.
- Много флагов → много ветвлений → сложнее тестировать.
Задача
Страховая компания предоставляет клиентам услуги по оформлению полисов.
Когда приходит запрос от клиента, нам нужно обратиться к сторонней SOAP-системе через HTTP, чтобы получить необходимые данные для расчёта.
По требованиям мы должны дать клиенту ответ в течение двух минут.
Если за это время расчёт не завершён — мы обязаны вернуть ошибку.
SOAP-система в среднем отвечает около 40 секунд, но работает нестабильно: иногда очень медленно, иногда вообще не отвечает.
Ожидаемая нагрузка — до 15 000 запросов в секунду, то есть система должна выдерживать высокий поток обращений и не зависеть от её нестабильности.
Решение
- Gate-way шлюз для авторизации и аутентификации пользователя(OAuth, Keycloak).
- Асинхронная модель(архитектура событий) - SOAP-система нестабильная, выдает ответ +-40 сек, SLA ≤ 2 минут - асинхронный подход максимально оправдан. Клиенту не нужно ждать - даёте taskId и он проверяет статус.
- Main-service - только бизнес-логика: создание задач, хранение статуса, оркестрация. Также он прослушивает ответ от adapter-service и timeout-service + main хранит информацию о сообщениях(outbox таблица).
- Adapter-service - работа с внешней системой, ретраи, circuit breaker, fallback.
- Timeout-service - только таймеры и SLA. (Я бы использовал delay queue для отслеживания таймера)
- Мы будем использовать kafka + outbox + de-dup таблица, чтобы гарантировать доставку и обработку 1 раз
- Outbox гарантирует доставку события.
- Идентификаторы сообщений — защита от дублей в потребителе.
- Kafka — выдержит твой TPS с огромным запасом.
- Для отслеживания состояний можно использовать distributed tracing
- Архивный топик(fan-out topic) - мы отбрасываем сообщения в отдельный топик, который на данный момент никто не слушает, чтобы была возможность к нему подключиться и прослушать все сообщения, даже, если kafka уже удалила их из другого топика.(Это можно сделать, если в будущем видится добавление сервисов обработки и есть на это доп ресурсы)
- Если в дальнейшем видится рост клиентов, можно использовать Kafka Streams для работы с большими данными
Микросервисная архитектура, я выделил несколько сервисов:
Задача 2
На e-commerce платформе в данный момент обрабатывает все операции (массовое создание и обновление заказов, поиск заказов клиентов, формирование сложных отчётов по продажам) через одну общую реляционную базу данных.
Во время пиковых нагрузок тяжёлые отчётные запросы вызывают серьёзные замедления транзакционных операций, что ухудшает пользовательский опыт.
Кроме того, сама модель данных заказов становится чрезмерно сложной, пытаясь одновременно удовлетворить разные потребности.
Вопросы
Какую ключевую архитектурную проблему этот пример демонстрирует в части работы с данными и почему единая модель данных не справляется?
Как вы бы переработали этот сервис, чтобы устранить проблемы с производительностью и избыточной сложностью? Назовите архитектурный паттерн и его основной принцип.
Ответ
CQRS решает эту задачу за счёт разделения моделей и баз данных для записи и чтения.
Запись (заказы): команды обновляют выделенную нормализованную базу для записи (оптимизированную под транзакции).
Чтение (отчёты): события записи асинхронно обновляют отдельную денормализованную базу для чтения (оптимизированную под быстрые запросы и отчётность).
CQRS чаще всего реализуется с использованием брокера сообщений.